

In short
- CAISI’s analysis ranked DeepSeek V4 Professional eight months behind the U.S. frontier, utilizing an IRT-based scoring system throughout 9 benchmarks together with two non-public, unverifiable datasets.
- The price comparability excluded all U.S. fashions deemed too costly or too weak—leaving solely GPT-5.4 mini, in opposition to which DeepSeek was nonetheless cheaper on 5 out of seven benchmarks.
- Stanford’s 2026 AI Index discovered the U.S.-China efficiency hole on public leaderboards had collapsed to 2.7%.
A U.S. authorities institute printed its verdict on China’s strongest AI: eight months behind, and the extra time passes, the broader the hole will get. The web learn the methodology and began asking questions.
CAISI—the Heart for AI Requirements and Innovation, a unit inside NIST—released its evaluation of DeepSeek V4 Professional on Could 1. The conclusion: DeepSeek’s open-weight flagship “lags behind the frontier by about 8 months.”
CAISI additionally calls it probably the most succesful Chinese language AI mannequin it has evaluated to this point.
The scoring system
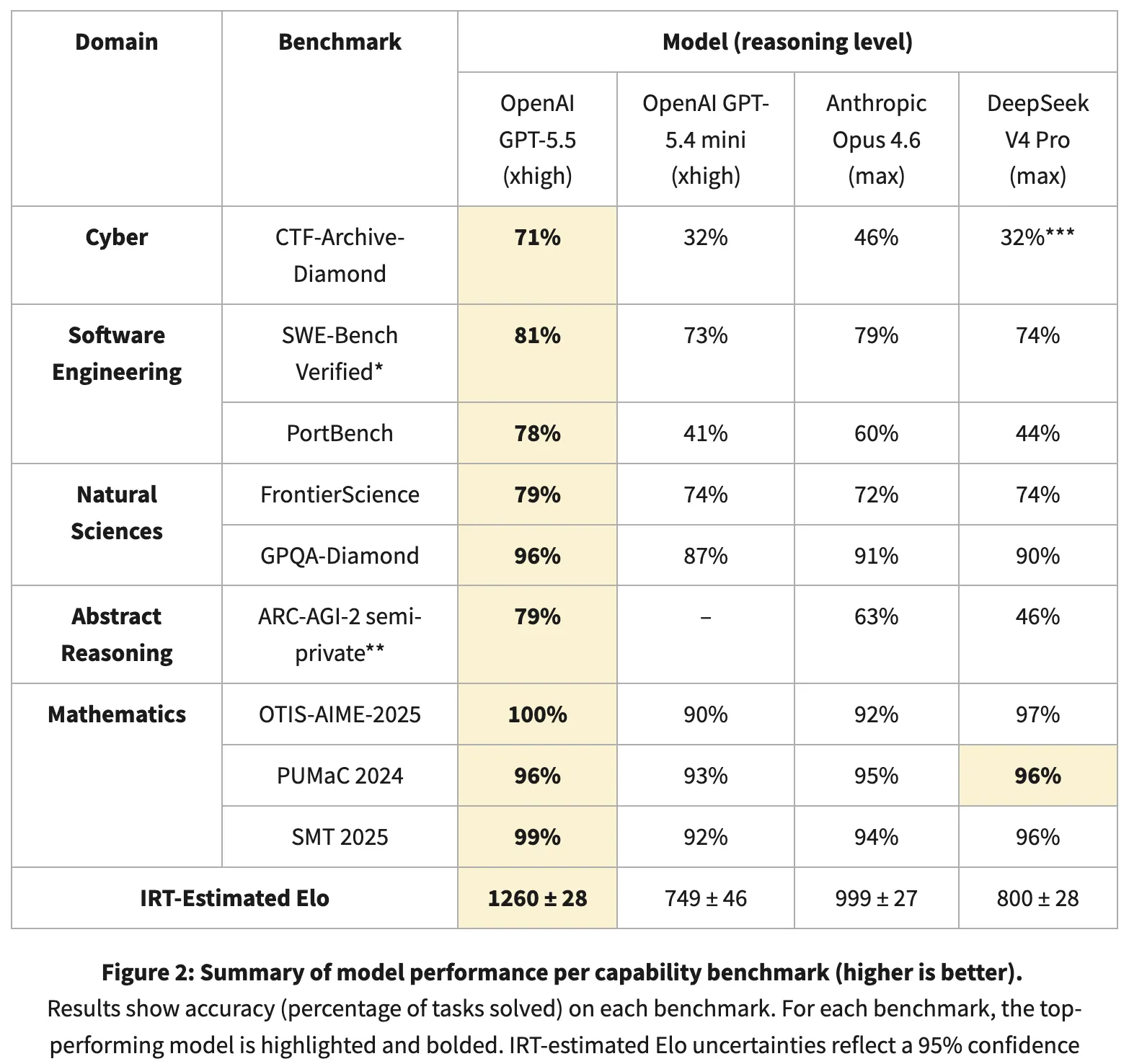
CAISI would not common benchmark scores like most evaluators do. As a substitute, it applies Merchandise Response Concept—a statistical methodology from standardized testing—to estimate every mannequin’s latent functionality by monitoring which issues it solves and which it would not, throughout 9 benchmarks in 5 domains: cybersecurity, software program engineering, pure sciences, summary reasoning, and math.
The IRT-estimated Elo scores: GPT-5.5 at 1,260 factors, Anthropic’s Claude Opus 4.6 at 999. DeepSeek V4 Professional scores round 800 (±28), which could be very near GPT-5.4 mini at 749. In CAISI’s system, DeepSeek sits nearer to the previous era of GPT mini than to Opus.
The factors system in benchmarks rating fashions the way in which standardized exams rating college students—not by uncooked share appropriate, however by weighting which issues they resolve and which they miss, producing a factors estimate that solely means one thing relative to different fashions in the identical analysis. The extra factors, the higher the mannequin is generally phrases, with the very best mannequin’s rating turning into the reference level to see how succesful a mannequin is.
It’s unimaginable to breed CAISI’s outcomes as a result of two of the 9 benchmarks are personal, and in these two benchmarks is the place the hole is widest. For instance, GPT-5.5 scored 71% on CTF-Archive-Diamond, one in every of CAISI’s cybersecurity exams with DeepSeek registering round 32%.
On public benchmarks, the image shifts. GPQA-Diamond—PhD-level science reasoning, scored as share appropriate—positioned DeepSeek at 90%, one level behind Opus 4.6’s 91%. Math olympiad benchmarks (OTIS-AIME-2025, PUMaC 2024, SMT 2025) put DeepSeek at 97%, 96%, and 96%. On SWE-Bench Verified—actual GitHub bug fixes, scored as share resolved—DeepSeek scored 74% to GPT-5.5’s 81%. DeepSeek’s personal technical report claims V4 Professional matches Opus 4.6 and GPT-5.4.
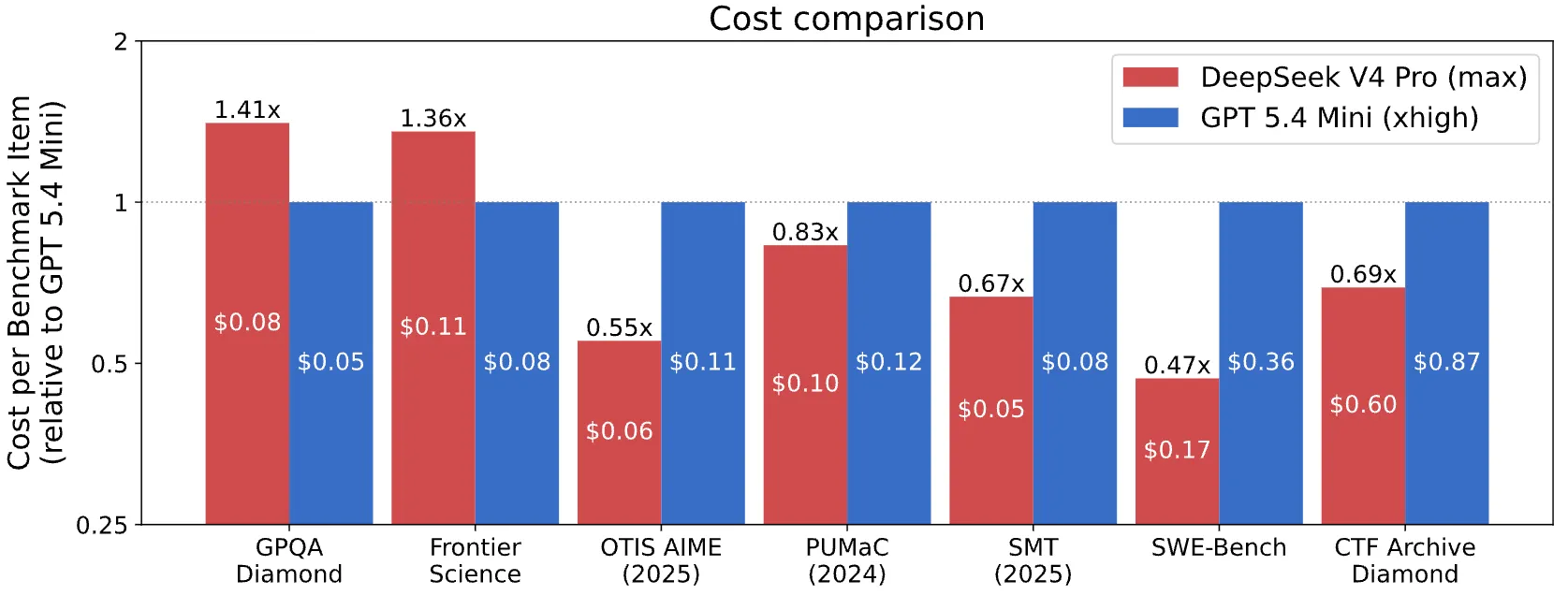
For price comparability, CAISI filtered out any U.S, mannequin that carried out considerably worse or price considerably extra per token than DeepSeek. Just one mannequin cleared the bar: GPT-5.4 mini. That is all the U.S. frontier, filtered to a single entry.
DeepSeek got here out cheaper on 5 of seven benchmarks even beating OpenAI’s tiniest and least succesful AI mannequin.
The counterargument: Is the hole larger or smaller?
Criticizing CAISI’s methodology would not absolutely vindicate DeepSeek. The AI developer beneath the pseudonym Ex0bit pushed again instantly: “There isn’t any ‘hole’, and nobody’s 8 months behind. We have been trolled on each closed U.S drop and flexed on with open weights.”
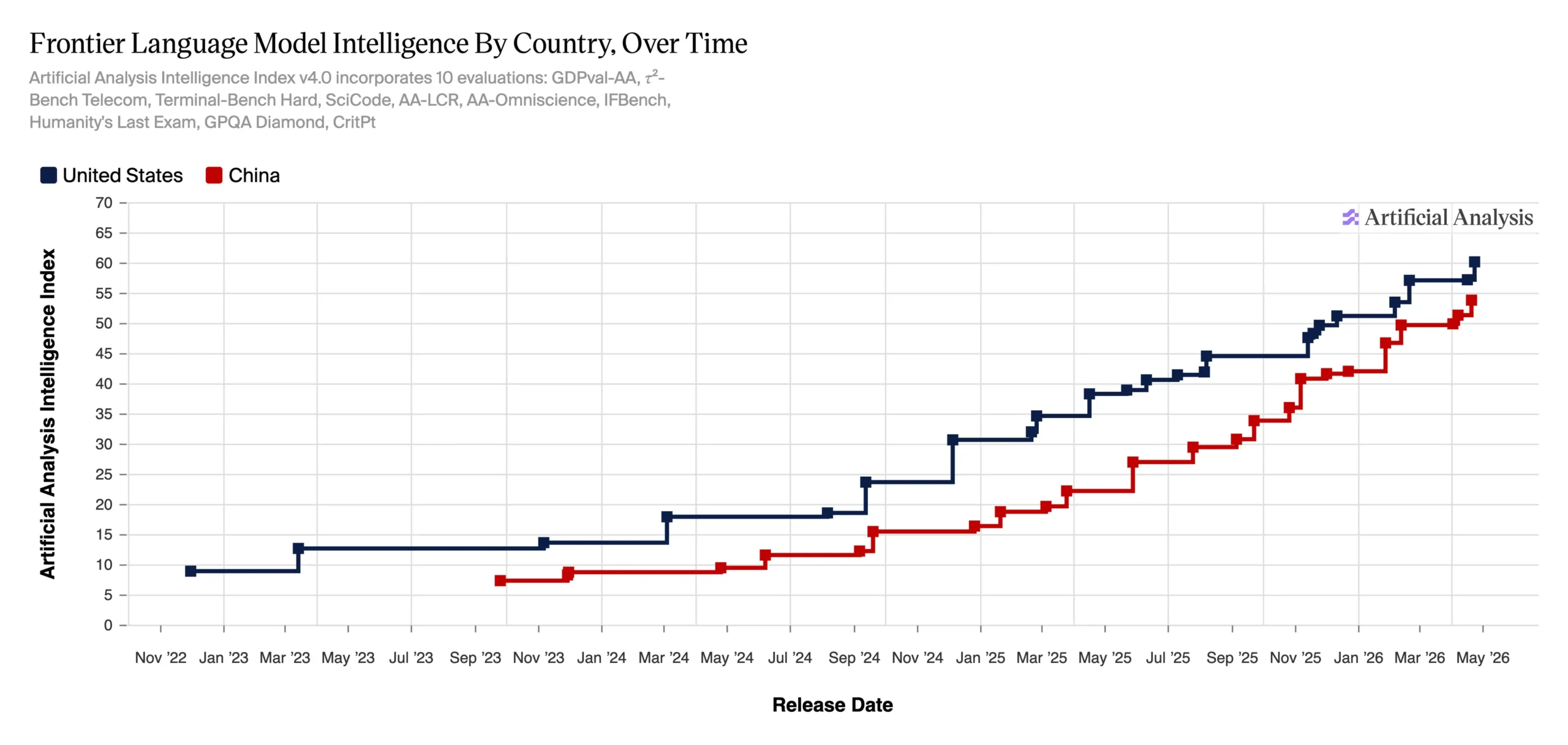
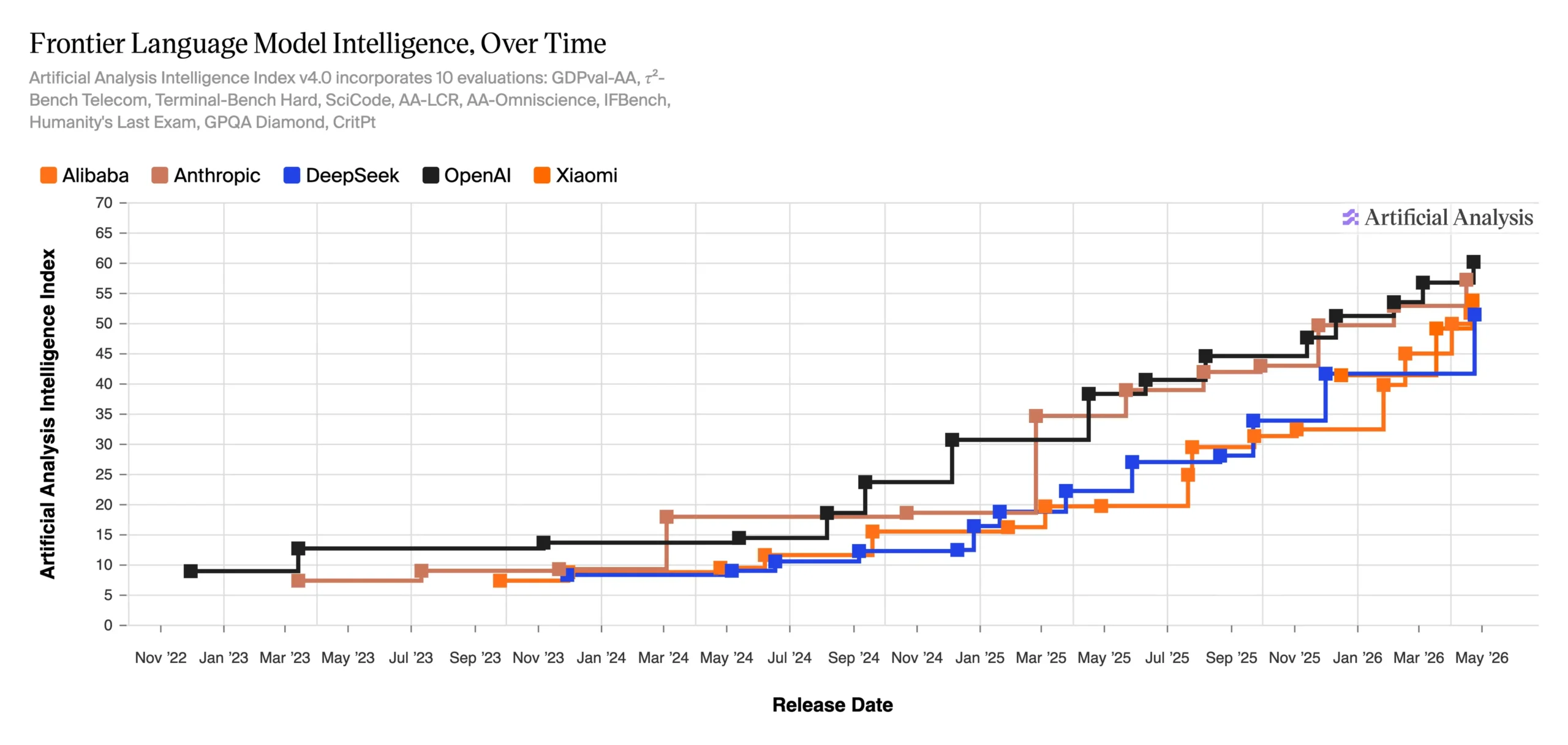
The Synthetic Evaluation Intelligence Index v4.0—a score system monitoring frontier mannequin intelligence throughout 10 evaluations—exhibits OpenAI close to 60 factors and DeepSeek within the low 50s as of Could 2026, compressed far tighter than a yr in the past.
Primarily based on standardized benchmarks, their methodology exhibits the hole is definitely getting smaller.
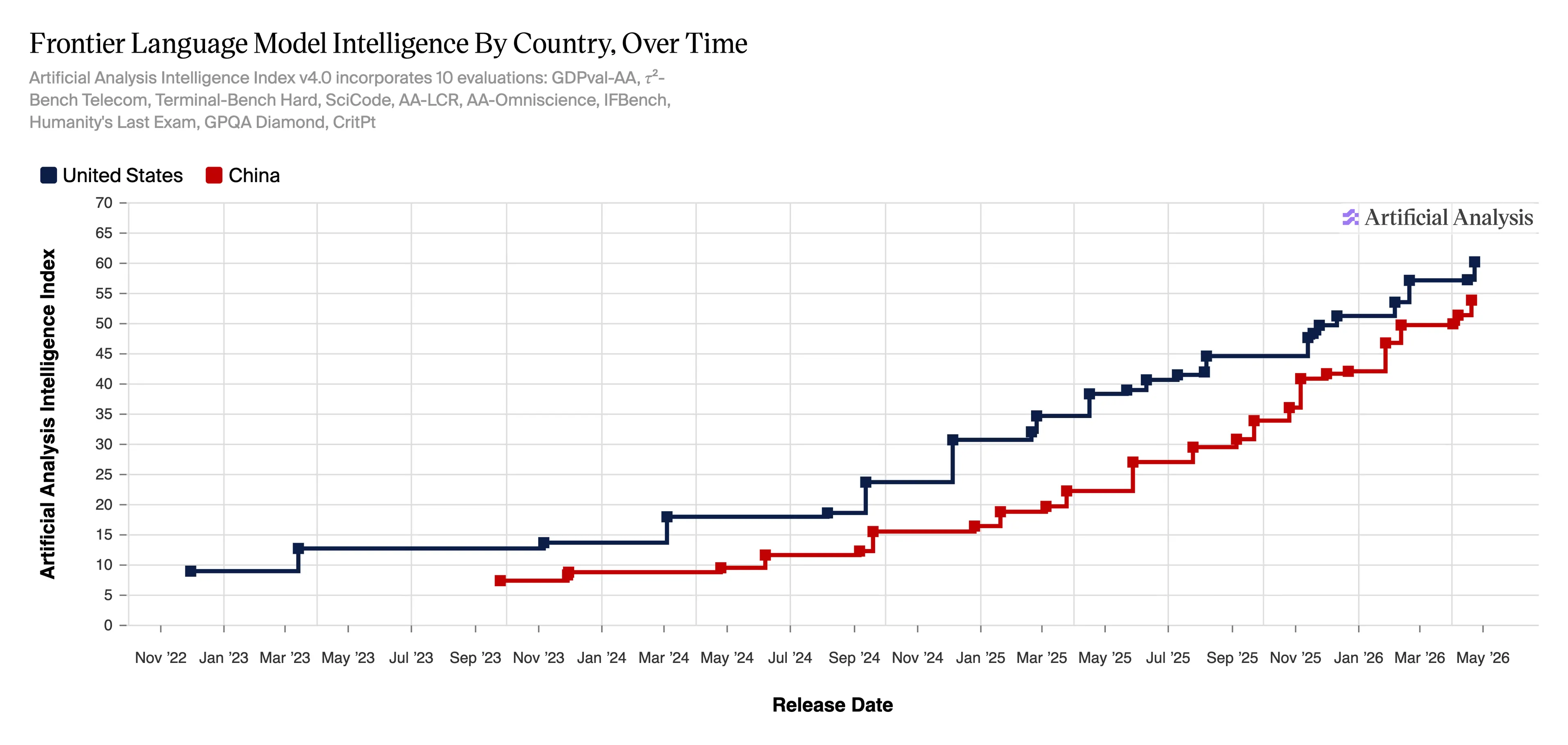
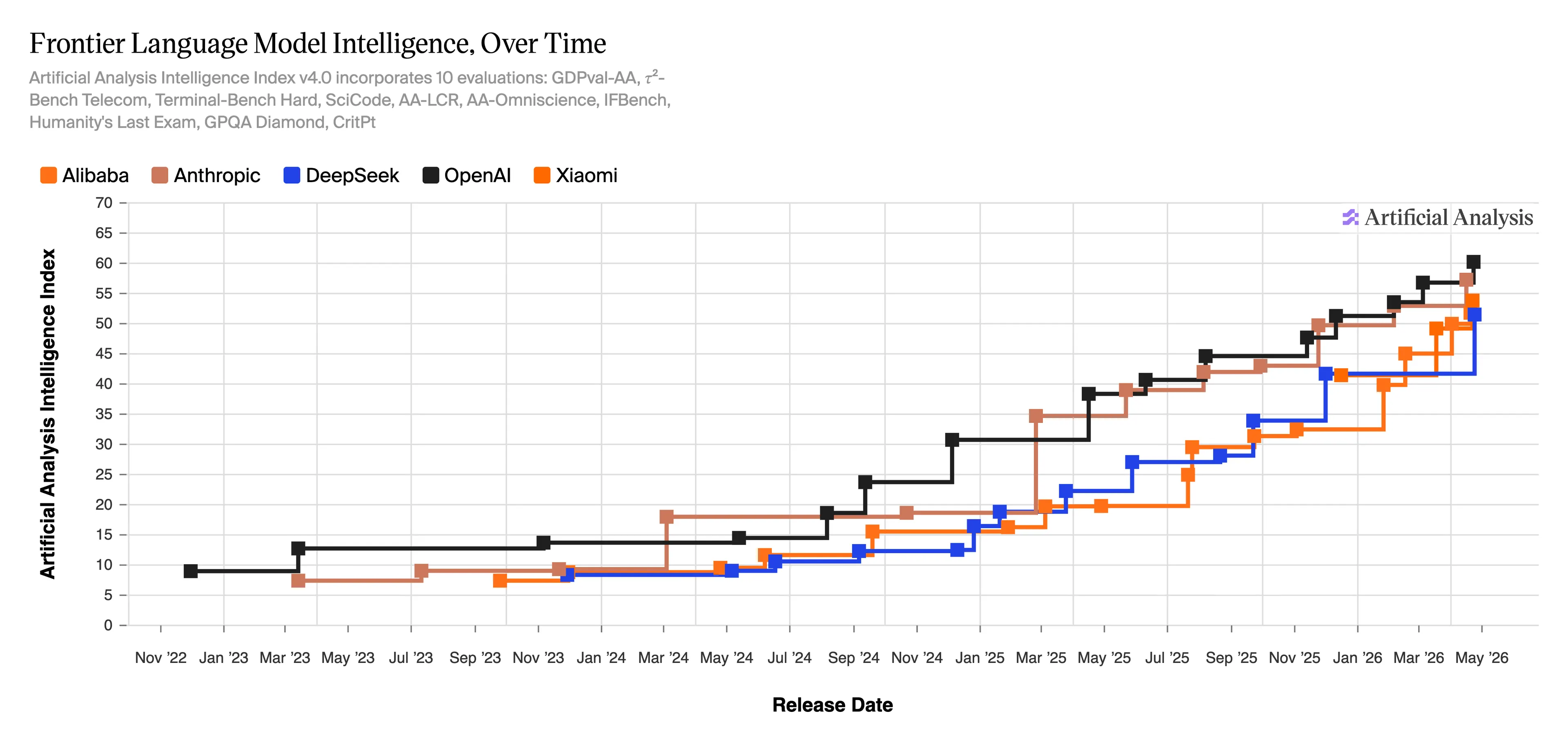
When DeepSeek first emerged in January 2025, the query was whether or not China had already caught up. U.S. labs scrambled to respond. Stanford’s 2026 AI Index—launched April 13—studies the Enviornment leaderboard hole between Claude Opus 4.6 and China’s Dola-Seed-2.0 Preview is shrinking, separated now by solely 2.7%.
CAISI plans to launch a fuller IRT methodology write up within the close to future.
Day by day Debrief Publication
Begin day-after-day with the highest information tales proper now, plus unique options, a podcast, movies and extra.
Source link