
A California man was in custody in reference to the capturing on the White Home Correspondents Dinner on Saturday night time on the Washington Hilton, President Trump mentioned throughout a information convention Saturday night time.
The person in custody has not been recognized publicly by the authorities, however two legislation enforcement officers aware of the investigation mentioned that he’s Cole Tomas Allen, 31, of Torrance, Calif. The officers requested to stay nameless as a result of that they had not been approved to reveal the data.
The suspect, who was apprehended by the Secret Service, was being charged with utilizing a firearm throughout a criminal offense of violence and with assault of a federal officer, mentioned Jeanine Pirro, the U.S. legal professional for the District of Columbia. She didn’t identify the suspect, however mentioned he could be arraigned on Monday in Federal District Courtroom and that further fees had been anticipated.
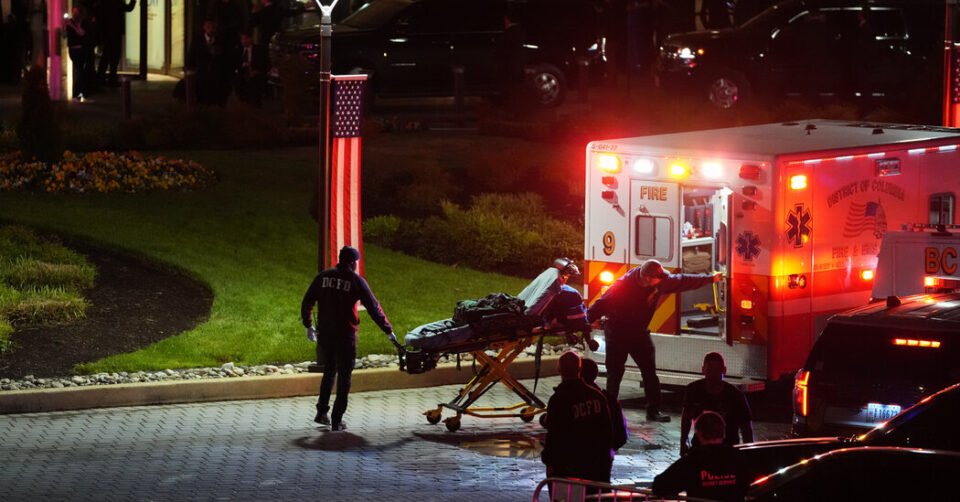
The suspect exchanged gunfire with authorities earlier than being introduced below management by the Secret Service. He didn’t attain the ballroom the place President Trump and lots of of members of the media had been gathered for the annual occasion, mentioned Washington Police Chief Jeffery W. Carroll in a separate information convention Saturday night time.
The suspect was carrying knives, a shotgun and a handgun, officers mentioned. He was believed to be staying as a visitor within the lodge when he carried out the assault, the authorities mentioned.
A Secret Service agent was shot, Mr. Trump mentioned, however he was protected by a bulletproof vest. He was taken to a hospital for remedy, officers mentioned. The suspect was additionally taken there to be evaluated, although officers mentioned they didn’t consider he had been injured.
“The person has been captured,” Mr. Trump mentioned throughout a briefing shortly after the capturing, including that investigators had been going to his residence in California. “He’s a really sick particular person.”
The authorities mentioned they believed the shooter acted alone. They had been nonetheless investigating whether or not the particular person was concentrating on the president.
A spokeswoman for the California Institute of Know-how mentioned an individual named Cole Allen had earned an undergraduate diploma in 2017, however that the varsity had no different data to reveal instantly.
A pupil named Cole Allen graduated with a grasp’s diploma from California State College, Dominguez Hills, in 2025, in response to a press release from that faculty.
“The college can not verify if this is identical suspect recognized within the April 25 capturing on the White Home Correspondents Dinner,” the assertion learn, including that the college “unequivocally condemns this act of violence, in addition to all types of violence.”
Alan Blinder and Chelsia Rose Marcius contributed reporting.