In short
- DeepSeek made its 75% V4-Professional low cost everlasting on Could 22, locking in output at $0.87 per million tokens.
- Xiaomi lower MiMo-V2.5 costs by as much as 99% on Could 26, with cached enter now at $0.0036 per million tokens for the Professional mannequin.
- OpenAI’s GPT-5.5 doubled output costs to $30 per million tokens at launch, and Anthropic’s Claude Opus 4.7 shipped with an up to date tokenizer that may inflate precise prices by as much as 35%.
DeepSeek made the 75% low cost on DeepSeek V4-Prowhich was set to run out, everlasting earlier this week. And now fellow Chinese language AI lab Xiaomi slashed MiMo-V2.5 API costs by as much as 99% for cached inputs. Two of essentially the most succesful AI fashions available on the market simply bought aggressively cheaper, whereas American labs moved in the wrong way.
Fast explainer for the non-developers within the room: While you use ChatGPT or Claude in a browser, you are paying a flat subscription—or nothing. When an organization builds a product on high of an AI mannequin, they pay per token, the place a token is roughly three-quarters of a phrase. Each message despatched, each reply generated, each doc processed: all of it provides up at a charge measured in thousands and thousands of tokens.
An API is the uncooked pipe that makes this attainable, making it attainable for an app, an agent, a website, and so on. to make use of the mannequin in their very own atmosphere. So token pricing determines whether or not an AI-powered product is economically viable or a cash pit.
Token plans are a subscription wrapper on high of that. You purchase credit upfront; the mannequin eats by means of them. Xiaomi’s billing improve provides customers 5 to eight occasions extra tokens on the similar worth. The Max plan at $100 now will get you 82 billion tokens, up from 1.6 billion.
For context, 82 billion tokens is greater than 60 billion phrases.
Why the cuts are actual, not advertising
Fuli Luo, head of Xiaomi’s MiMo workforce and a former core DeepSeek developer who co-built DeepSeek-V2, revealed a technical rationalization on X. The most important financial savings come from a wiser means of storing and reusing info the AI has already processed. As an alternative of repeatedly doing the identical work, Xiaomi’s system can keep in mind way more knowledge directly—about 5 occasions greater than earlier than. Which means the AI wants far much less computing energy, reducing storage and processing prices by round 80%.
Behind the MiMo API Worth Discount:
The deepest worth lower, as much as 99%, is for Enter (Cache Hit). The core purpose is our inference framework now helps hierarchical KV cache optimization for SWA. Manufacturing inference engine exams present this optimization will increase cached token…— Fuli Luo (@_LuoFuli) May 27, 2026
“Working at these newly lowered API costs, our manufacturing inference engine is working at close to full capability, and we will nonetheless primarily break even,” Luo wrote. “If extra architectures that save compute and KV (Key-Worth cache) cache emerge, together with higher inference Infra to drive down API prices, this may type a wonderful virtuous cycle within the trade.”
DeepSeek’s structure lands in the same place in another way. V4 makes use of two interleaved consideration sorts—one compressing each 4 tokens for selective consideration, one other collapsing each 128 tokens for world context at minimal compute. At a million tokens of context, V4-Professional’s KV cache is 10% the dimensions of its predecessor’s, and single-token inference runs at 27% of the earlier compute value.
The result’s a mannequin 98% cheaper than GPT-5.5 Professional with a aggressive efficiency.
Silicon Valley’s guess
Claude Opus 4.7 prices $5 per million enter tokens and $25 per million output tokens. Anthropic stored the speed card flat however shipped it with a brand new tokenizer that may produce up to 35% more tokens for a similar enter textual content. So the worth did not go up. Your invoice nonetheless may.
GPT-5.5, released in late Aprilsimply doubled its predecessor’s output worth to $30 per million tokens. Gemini 2.5 Professional sits at $1.25 enter and $10 output—low-cost by American requirements.
DeepSeek V4-Professional is a 1.6 trillion parameter mannequin that offers you the data base of a large mannequin at a fraction of the compute value. It now completely runs at $0.435 enter and $0.87 output per million tokens. That is a mannequin that scored 80.6% on SWE-Verified towards Claude Opus 4.6’s 80.8%—a benchmark measuring actual GitHub challenge decision, not cherry-picked demos. The pricing hole between fashions with primarily the identical coding rating: 34x on output.
MiMo V2.5 Pro matches that very same $0.435/$0.87 per million tokens after the brand new cuts. Cache hits drop to $0.0036. For context, that is cheaper per token than most individuals pay per character in an SMS.
DeepSeek and Xiaomi aren’t alone
These cuts landed in a market the place Chinese language fashions had been already much cheaper earlier than any of this. MiniMax M2.7, which trades punches with Claude Opus on coding benchmarks per Synthetic Evaluation, prices $0.30 enter and $1.20 output per million tokens—about 5% of Opus 4.7’s output charge.
Kimi K2.5 from Moonshot AI, with 76.8% on SWE-bench Verified, runs $0.60 enter and $2.50 output. GLM-5.1 from Z.AI beat Claude Opus 4.6 on a key coding benchmark earlier this quarter. 4 Chinese language frontier fashions shipped in a 12-day window in early Could, all below one-third of Opus 4.7’s per-token value.
For higher visualization, this chart exhibits how Chinese language fashions stack up towards the three hottest American AI suppliers (Anthropic, OpenAI, and Meta) by way of worth to high quality ratio.
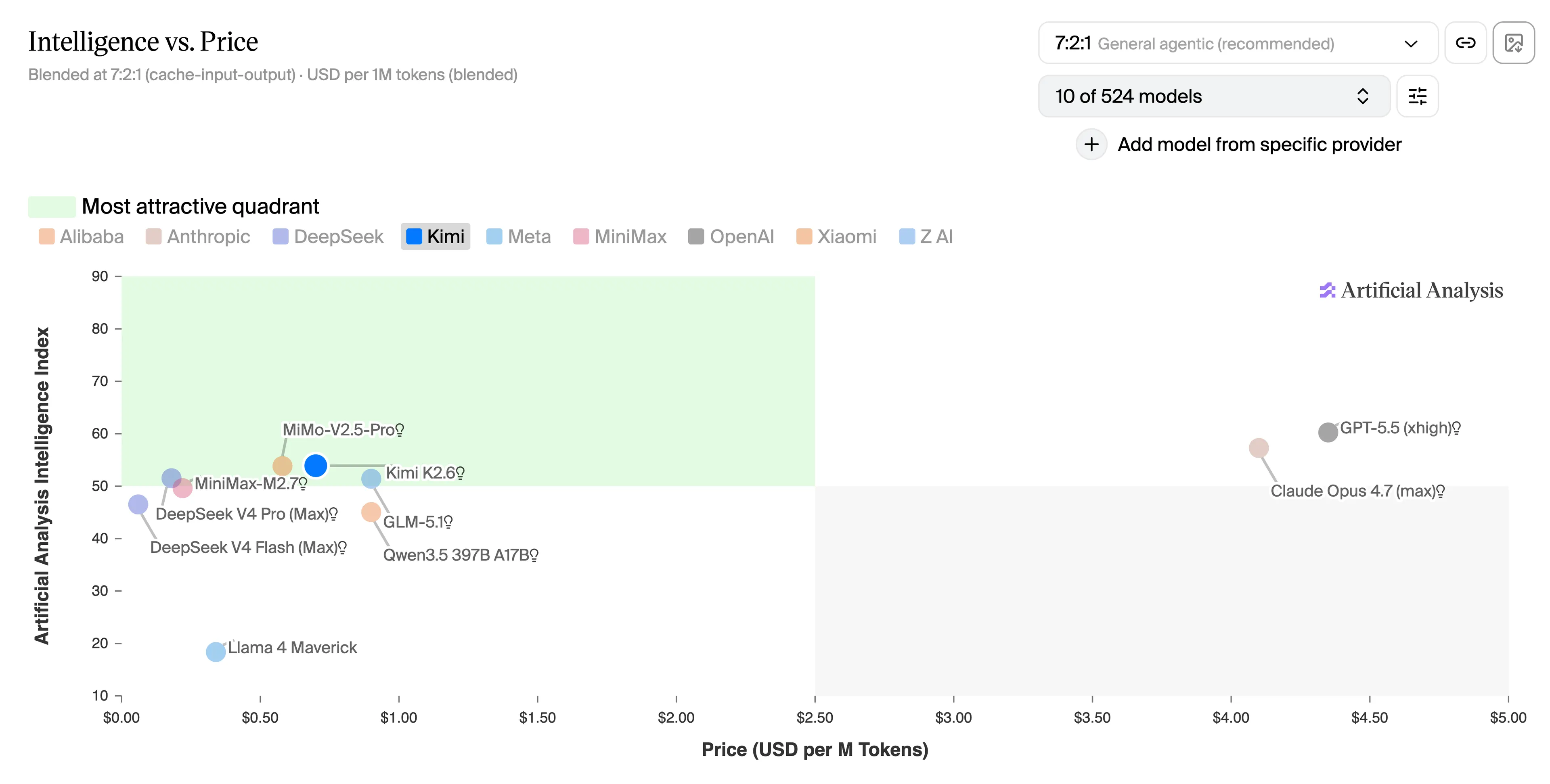
The Q2 2026 hole between Chinese language and American frontier fashions sits at 15–30x, relying on which fashions you examine—and that is the baseline, earlier than any cache reductions.
What this week’s cuts do is collapse that hole additional for the particular workloads that truly run in manufacturing: agent pipelines with secure system prompts, doc processors, retrieval instruments, issues that hit cache consistently. At $0.003625 per million cached enter tokens, DeepSeek V4-Professional’s value for repeated context is functionally rounding error.
Each day Debrief Publication
Begin every single day with the highest information tales proper now, plus authentic options, a podcast, movies and extra.